C++ STL, Boost and native array Performance and Custom Allocator
(Updated: Jan 2015)
landenlabs.com
Dennis Lang
[ To Home Page ]
Contents [ Updated reports and code Jan-2015, latest vs2013 update4]
Includes comparison with Boost 1.57
The following performance results compare various STL containers and Boost, using several compilers.
The code includes
custom allocators for std node based contains such as
std::map.
Lastly there is a comparison of compiled code execution generated by several Microsoft Visual Studio compilers.
Array performance measures the impact of bounds checking on stl::vector and compares its three common access operators.
Visual Studio 2008 has STL bounds checking enabled by default in Release build while VS2010 and newer have it disabled.
The removal of bounds checking in Release builds significantly improves performance.
Two array tests are measured:
| Update Performance: | container[i] = container[i] + n;
|
| Read Access: | total += container[i];
|
The Update Performance test measures the performance to read and write a value in a container object.
The measurments are collected on four different containers:
- native C/C++ array, example int array[100];
- STL vector, example std::vector<int>(100);
- Boost vector, example boost::container::vector<int>(100);
- Custom templated vector like class, example DataVector<int>(100);
The custom container DataVector is similar to std::vector but lacks the bounds checking and provides an iterator as a pointer.
The Read Access test measures read access only and use 12x more iterations than Update test.
The measurements are collected on three different access methods:
- random access operator[]
- random access method at()
- sequencial access via an iterator
Array Performance Details
The results are grouped into three tables:
- Update Performance
- std::vector Read Access
- boost::vector Read Access
Notice that both x86 and x64 targets are built and test is run on Windows 7/x64.
The x64 targets run faster then x86 on Windows 7/x64.
DataVector is a custom container similar to std::vector but has no bounds checking, so the
bounds checking measurements are not computed.
Bounds checking defaults to on with VS2008 and off for others.
The Elapsed column reflects a unitless elapsed clock ticks.
The larger the number the longer the duration and the worse the performance.
The Ratio column reflects the ratio of the elapsed ticks compared to the fastest item in the test group.
A value of 1 means it performs as well as the best in the group. A value of 2 is 2 times slower.
Graph compares relative performance of Update Access
DataVector is custom container with no Bounds Checking.
Default Release build settings for Visual Studio, Boost 1.57
Hardware: HP xw8600 dual quad cord Intel Xeon E5444 2.83 Ghz on Windows 7/x64
- Raw array is fastest, but the gap closes with the newer compilers.
- Boost::vector and std::vector are similar
- VS2008 has bounds checking ON others default OFF.

Zoomed in graph excluding Vs2008.

Microsoft's std::vector Read Access built with Visual Studio
- Array operator continues to be fastest Read interface followed by iterator and at().

Boost v1.57 Vector Read Access built with Visual Studio

Code compiled with default Release optimization
Ratio is elapsed #ticks divided by smallest #ticks in table to give a Ratio of performance.
All tests run on HP xw8600 dual quad core Xeon E5440@ 2.83 Ghz
Run on Windows 7/x64
Set to 8,000 iterations for Update and 96,000 for Read access
Elapsed
#ticks | Ratio | Container Object | Bounds
Checking | Compiler
/Target
|
| Update Performance obj[i]=obj[i] + n
|
| 7,598 | 8.2 | array[i] | Yes | VS2008/x64
|
| 7,614 | 8.3 | array[i] | Yes | VS2008/x86
|
| 925 | 1.0 | array[i] | No | VS2010/x64
|
| 1,648 | 1.8 | array[i] | No | VS2010/x86
|
| 939 | 1.0 | array[i] | No | VS2013/x64
|
| 1,652 | 1.8 | array[i] | No | VS2013/x86
|
|
|
| 15,997 | 17.4 | DataVector[i] | No | VS2008/x64
|
| 20,378 | 22.1 | DataVector[i] | No | VS2008/x86
|
| 925 | 1.0 | DataVector[i] | No | VS2010/x64
|
| 1,888 | 2.0 | DataVector[i] | No | VS2010/x86
|
| 942 | 1.0 | DataVector[i] | No | VS2013/x64
|
| 1,767 | 1.9 | DataVector[i] | No | VS2013/x86
|
|
|
| 28,240 | 30.6 | std::vector[i] | Yes | VS2008/x64
|
| 38,503 | 41.8 | std::vector[i] | Yes | VS2008/x86
|
| 936 | 1.0 | std::vector[i] | No | VS2010/x64
|
| 1,915 | 2.1 | std::vector[i] | No | VS2010/x86
|
| 943 | 1.0 | std::vector[i] | No | VS2013/x64
|
| 1,804 | 2.0 | std::vector[i] | No | VS2013/x86
|
|
|
| 21,249 | 23.0 | boost::vector[i] | Yes | VS2008/x64
|
| 33,801 | 36.7 | boost::vector[i] | Yes | VS2008/x86
|
| 923 | 1.0 | boost::vector[i] | No | VS2010/x64
|
| 1,839 | 2.0 | boost::vector[i] | No | VS2010/x86
|
| 922 | 1.0 | boost::vector[i] | No | VS2013/x64
|
| 1,978 | 2.1 | boost::vector[i] | No | VS2013/x86
|
Elapsed
#Ticks | Ratio | Container Object | Bounds
Checking | Compiler
/Target
|
| std::vector Read Access
|
| 21,625 | 15.5 | std::vector[i] | Yes | VS2008/x64
|
| 26,443 | 18.9 | std::vector[i] | Yes | VS2008/x86
|
| 1,525 | 1.1 | std::vector[i] | No | VS2010/x64
|
| 1,611 | 1.2 | std::vector[i] | No | VS2010/x86
|
| 1,522 | 1.1 | std::vector[i] | No | VS2013/x64
|
| 1,397 | 1.0 | std::vector[i] | No | VS2013/x86
|
|
|
| 196,639 | 140.8 | std::vector.at(i) | Yes | VS2008/x64
|
| 105,111 | 75.2 | std::vector.at(i) | Yes | VS2008/x86
|
| 1,914 | 1.4 | std::vector.at(i) | Yes | VS2010/x64
|
| 1,846 | 1.3 | std::vector.at(i) | Yes | VS2010/x86
|
| 1,914 | 1.4 | std::vector.at(i) | Yes | VS2013/x64
|
| 1,765 | 1.3 | std::vector.at(i) | Yes | VS2013/x86
|
|
|
| 48,673 | 34.8 | std::vector::iterator | Yes | VS2008/x64
|
| 56,947 | 40.8 | std::vector::iterator | Yes | VS2008/x86
|
| 1,863 | 1.3 | std::vector::iterator | No | VS2010/x64
|
| 1,767 | 1.3 | std::vector::iterator | No | VS2010/x86
|
| 1,870 | 1.3 | std::vector::iterator | No | VS2013/x64
|
| 1,987 | 1.4 | std::vector::iterator | No | VS2013/x86
|
Elapsed
#Ticks | Ratio | Container Object | Bounds
Checking | Compiler
/Target
|
| boost::vector Read Access
|
| 15,753 | 11.3 | boost::vector[i] | No | VS2008/x64
|
| 23,315 | 16.8 | boost::vector[i] | No | VS2008/x86
|
| 1,520 | 1.1 | boost::vector[i] | No | VS2010/x64
|
| 1,607 | 1.2 | boost::vector[i] | No | VS2010/x86
|
| 1,521 | 1.1 | boost::vector[i] | No | VS2013/x64
|
| 1,390 | 1.0 | boost::vector[i] | No | VS2013/x86
|
|
|
| 19,151 | 13.8 | boost::vector.at(i) | Yes | VS2008/x64
|
| 30,230 | 21.7 | boost::vector.at(i) | Yes | VS2008/x86
|
| 1,912 | 1.4 | boost::vector.at(i) | Yes | VS2010/x64
|
| 1,756 | 1.3 | boost::vector.at(i) | Yes | VS2010/x86
|
| 1,913 | 1.4 | boost::vector.at(i) | Yes | VS2013/x64
|
| 1,770 | 1.3 | boost::vector.at(i) | Yes | VS2013/x86
|
|
|
| 16,863 | 12.1 | boost::vector::iterator | No | VS2008/x64
|
| 24,542 | 17.7 | boost::vector::iterator | No | VS2008/x86
|
| 1,914 | 1.4 | boost::vector::iterator | No | VS2010/x64
|
| 1,766 | 1.3 | boost::vector::iterator | No | VS2010/x86
|
| 1,869 | 1.3 | boost::vector::iterator | No | VS2013/x64
|
| 1,987 | 1.4 | boost::vector::iterator | No | VS2013/x86
|
Array Performance Conclusion
- With the latest vs2013 compiler, using Release build with bounds checking off
the raw array and vector access performance is pratically identical.
- x64 target builds run faster on Windows7/x64 OS.
- Boost and Microsoft STL Vector performance is similar.
- Microsoft allows bounds checking to be enabled/disabled by setting precompiler macro _SECURE_SCL.
- Microsoft default bounds checking was ON in Release builds of VS2008 but is now off in newer compilers.
- The array read performance continues to be in the following order:
- operator [] [fastest]
- iterator
- vector.at(idx) [slowest]
[ Top ]
Sections covered in this article:
Contaners
This article compares how STL containers perform when used to count duplicate words (strings).
The speed and memory allocation calls are measured.
The following containers are compared:
| Hash Map | stdext::hash_map<std::string, int>
|
| Map | std::map<std::string, int>
|
| Hash MultiMap | stdext::hash_multimap<std::string, int>
|
| Multimap | std::multimap<std::string, int>
|
| Vector | std::vector< std::pair<std::string, int> >
|
| Deque | std::deque< std::pair<std::string, int> >
|
The first two containers are also tested using a custom allocator which allocates in
larger chunks and reuses freed nodes.
The Vector container is also tested with the aid of sorting and a binary search.
The following Boost 1.57 Containers have been added to the test suite.
| Map | boost::container::map<std::string, int>
|
| Flat Map | boost::container::flat_map<std::string, int>
|
| Multimap | boost::container::multimap<std::string, int>
|
| Vector | boost::container::vector< std::pair<std::string, int> >
|
| Deque | boost::container::deque< std::pair<std::string, int> >
|
Test Engine
The ordered containers use the following test engine to fill, search, and count duplicate words.
Ordered Test Engine:
///////////////////////////////////////////////////////////////////////////////
/// Exercise ordered containers
///
/// 1. Add words to container until it has 'groupSize' elements.
/// 2. Scan remainder of words counting duplicate.
/// 3. When scanning sLookupScale * groupSize words, clear list and goto #1
template <typename Container_t>
size_t Test(const Words& words, size_t groupSize, const char* objName, size_t& mallocCnt)
{
Container_t container;
size_t lookupCnt = 0;
size_t cnt = words.size();
// One shot pre-allocation value use to allocate next set of data nodes.
// Afterwards it goes back to sAllocRate which is 16.
container.get_allocator().SetPrealloc(groupSize);
typename Container_t::iterator found;
for (size_t idx = 0; idx < cnt; idx++)
{
const std::string& word = words[idx];
if (container.size() < groupSize)
{
// Fill - find dup and count, else add new word.
found = container.find(word);
if (found != container.end())
found->second++; // count duplicates
else
container.insert(PairSI(words[idx], 1));
}
else
{
// Find dup and count, else ignore.
found = container.find(word);
if (found != container.end())
found->second++; // only count duplicates
// Occassionally empty list and repeat fill cycle.
if (++lookupCnt == groupSize * sLookupScale)
{
lookupCnt = 0;
container.clear();
}
}
}
mallocCnt = container.get_allocator().GetAllocCnt();
// The following is diagnostic code to sum word count and return its value
// to compare to other containers to make sure all instances return the same value.
size_t total = 0;
for (typename Container_t::const_iterator iter = container.begin(); iter != container.end(); ++iter)
{
total += iter->second;
}
return total;
}
Custon Allocator
The custom allocate is geared towards node containers such as
map.
If a multiple element request is made, it by-passes the custom logic and falls into
malloc and free adding no benefit.
Single element requests will either provide a response from the free list or allocate a
group of objects using malloc, returning one of them and placing the remainder on the free list.
If the container never erases elements and only grows, there will be only a small improvement due
to the chunking of allocations (16 per call to malloc).
The biggest gains with this allocator is achieved when the free-list provides a quick response
when the client balances calls to insert with erase.
The Test Engine above has been geared towards doing just this, it periodically clears and refills the container.
The custom allocator uses a reference counted SharedInfo object to track its private data.
This shared object allows containers like map to create multiple allocator
instances of different sizes and still provide statistics to the client code and cleanup correctly.
Map can create 3 different allocators which come and go independent of their allocation requests.
Meaning the state information could be lost by the time you are done using the Map if it were not shared
between the allocators.
Even with the allocator's shared information, it is still associated with a single container. Meaning it is not
a global pool used across multiple STL containers.
This custom allocator has no thread protection. STL containers are are not thread safe.
Custom Allocator (for node containers such as Map, MultiMap, HashMap, etc):
Update: Sept, 15th 2013 - Fixed memory leak
Thank you to Marian Kechlibar for detecting a memory leak using valgrind and subsequent verification the leak was fixed.
///////////////////////////////////////////////////////////////////////////////
// Interface for Allocator
class IAlloc
{
public:
virtual size_t GetAllocCnt() const = 0;
typedef size_t size_type;
// Optionally
// One shot pre-allocation value use to allocate next set of data nodes.
// Afterwards it goes back to sAllocRate which is 16.
virtual void SetPrealloc(size_type numElements)
{ }
};
///////////////////////////////////////////////////////////////////////////////
// Custom allocator - groups allocation in chunks of 16.
// Recyles deleted nodes by placing them on free list and using them for allocations.
template <class TT>
class PoolAlloc : public IAlloc
{
// Rate to allocate extra objects.
static const unsigned sAllocRate = 16;
public:
typedef size_t size_type;
typedef ptrdiff_t difference_type;
typedef TT* pointer;
typedef const TT* const_pointer;
typedef TT& reference;
typedef const TT& const_reference;
typedef TT value_type;
template <class UU>
struct rebind
{
typedef PoolAlloc<UU> other;
};
// Wrapper to add singly link list pointers to track next
// free object and allocated pointers.
class Wrapper
{
public:
Wrapper() : pNext(0), pAlloc(0)
{ }
Wrapper* pNext;
Wrapper* pAlloc;
// Place client data at end since its size can vary becaue
// std::map has several internal lists of varying structure.
#if 1
char value[sizeof(TT)]; // reserve size for TT, avoid its constructor
#else
TT value; // Safer, but slower
#endif
};
// Allocator shared state information.
class SharedInfo
{
public:
SharedInfo() : allocCnt(0), numToAlloc(sAllocRate), refCnt(1), pAlloc(0)
{ }
~SharedInfo()
{ FreeList(); }
size_t allocCnt; // DEBUG - track number of allocations
size_t numToAlloc; // # of allocations in next malloc, used to preallocate.
int refCnt; // Reference counter, std::map has multiple internal list which share this info.
Wrapper* pAlloc; // List of all allocations
void FreeList()
{
// Free any allocations (follow pAlloc link list)
while (pAlloc != NULL)
{
Wrapper* pNext = pAlloc->pAlloc;
free(pAlloc);
pAlloc = pNext;
}
}
};
SharedInfo* pSharedInfo;
Wrapper* pFree;
PoolAlloc() throw() : pSharedInfo(new SharedInfo()), pFree(0)
{ }
PoolAlloc(const PoolAlloc& other) : pSharedInfo(other.pSharedInfo), pFree(0)
{ pSharedInfo->refCnt++; }
template <class U>
PoolAlloc(const PoolAlloc<U>& other) : pSharedInfo((SharedInfo*)other.pSharedInfo), pFree(0)
{ pSharedInfo->refCnt++;}
bool operator==(const PoolAlloc& other)
{ return pSharedInfo == other.pSharedInfo; }
~PoolAlloc () throw()
{ if (--pSharedInfo->refCnt == 0) delete pSharedInfo; }
// Return number of calls to malloc executed so far.
size_t GetAllocCnt() const
{ return pSharedInfo->allocCnt; }
// One shot pre-allocation value use to allocate next set of data nodes.
// Afterwards it goes back to sAllocRate which is 16.
void SetPrealloc(size_type numToAlloc)
{
pSharedInfo->numToAlloc = numToAlloc;
}
// Pre-allocate nodes on free-list.
void Preallocate(size_type numElements)
{
pSharedInfo->allocCnt++;
// malloc faster than new[], avoids constructors
Wrapper* pWrapper = (Wrapper*)malloc(numElements * sizeof(Wrapper));
pWrapper->pNext = 0;
// Keep track of allocated memory, wire up link list.
pWrapper->pAlloc = pSharedInfo->pAlloc;
pSharedInfo->pAlloc = pWrapper;
// Split up allocation and store on free list.
for (unsigned idx = 0; idx != numElements; idx++)
{
pWrapper->pNext = pFree;
pFree = pWrapper;
pWrapper++;
}
}
pointer address(reference x) const
{ return &x; }
const_pointer address(const_reference x) const
{ return &x; }
pointer allocate(size_type numElements, typename PoolAlloc<TT>::const_pointer hint = 0)
{
if (numElements != 1)
{
// Pass multile element allocation directly to malloc, no special handling.
pSharedInfo->allocCnt++;
return static_cast<pointer>(malloc(numElements * sizeof(TT)));
}
if (pFree == NULL)
{
if (pSharedInfo->allocCnt > 4)
{
// Once we have complete basic setup, allocate in larger chunks.
Preallocate(pSharedInfo->numToAlloc);
pSharedInfo->numToAlloc = sAllocRate;
}
else
{
// During setup, allocate in small chunks.
Preallocate(1);
}
}
if (pFree == NULL)
return 0; // or should we throw.
Wrapper* pWrapper = pFree;
pFree = pWrapper->pNext;
pWrapper->pNext = (Wrapper*)0;
return (TT*)&pWrapper->value;
}
void deallocate(pointer ptr, size_type numElements)
{
if (numElements != 1)
{
// Pass multi-element allocation directly to free.
free(ptr);
}
else
{
// Place memory on free list.
const size_t sToWrapper = offsetof(Wrapper, value);
Wrapper* pWrapper = (Wrapper*)((char*)ptr - sToWrapper);
pWrapper->pNext = pFree;
pFree = pWrapper;
}
}
size_type max_size() const throw()
{ return size_t(-1) / sizeof(value_type); }
void construct(pointer p, const TT& val)
{ new(static_cast<void*>(p)) TT(val); }
void construct(pointer p)
{ new(static_cast<void*>(p)) TT(); }
void destroy(pointer p)
{ p->~TT(); }
};
Custon Allocator Counts Memory Calls (malloc)
The following custom allocator exists just to count malloc calls. It has no performance benefits.
This single allocator should work with all STL containers.
///////////////////////////////////////////////////////////////////////////////
// Custom allocator - counts memory allocation calls.
template <class T>
class CountAlloc
{
public:
typedef size_t size_type;
typedef ptrdiff_t difference_type;
typedef T* pointer;
typedef const T* const_pointer;
typedef T& reference;
typedef const T& const_reference;
typedef T value_type;
template <class U>
struct rebind
{
typedef CountAlloc<U> other;
};
struct SharedInfo
{
public:
SharedInfo() : allocCnt(0), refCnt(1)
{ }
size_t allocCnt;
int refCnt;
};
SharedInfo* pSharedInfo;
CountAlloc () throw() : pSharedInfo(new SharedInfo())
{ }
CountAlloc (const CountAlloc& other) : pSharedInfo(other.pSharedInfo)
{ pSharedInfo->refCnt++; }
template <class U>
CountAlloc(const CountAlloc<U>& other) : pSharedInfo((SharedInfo*)other.pSharedInfo)
{ pSharedInfo->refCnt++;}
bool CountAlloc::operator==(const CountAlloc& other)
{ return this == &other; }
~CountAlloc ()
{ if (--pSharedInfo->refCnt == 0) delete pSharedInfo; }
size_t GetAllocCnt() const
{ return pSharedInfo->allocCnt; }
pointer address(reference x) const
{ return &x; }
const_pointer address(const_reference x) const
{ return &x; }
pointer allocate(size_type size, typename CountAlloc<T>::const_pointer hint = 0)
{
pSharedInfo->allocCnt++;
return static_cast<pointer>(malloc(size * sizeof(T)));
}
void deallocate(pointer p, size_type n)
{
free(p);
return;
}
size_type max_size() const throw()
{ return size_t(-1) / sizeof(value_type); }
void construct(pointer p, const T& val)
{ new(static_cast<void*>(p)) T(val); }
void construct(pointer p)
{ new(static_cast<void*>(p)) T(); }
void destroy(pointer p)
{ p->~T(); }
};
Test Results
The performance results are measured using data acquired by reading the "source code" of the this test program and parsing into a vector of words.
Here is an analysis of the input data set:
| Input Word | Analysis:
|
| 40743 | words
|
| 1409 | unique words
|
| 28 | average #duplicates
|
| 6 | average length
|
| 39 | maximum length
|
Group Size is the maximum size the container is allowed to grow during the process of counting duplicate words.
The test input contains 1409 unique words, so any container smaller than this will fail to count some words.
The larger the Group Size the larger the container and the harder it works to find duplicates.
The graph and report plot the ratio of the elapsed time of the test divided by the elapsed time of the fastest test.
Smaller ratio values are faster, with 1.00 the fastest. A ratio value of 2 is twice as slow as the fastest.
The following results are with 4 background threads running the same test in parallel as the foreground test.
The background threads are used to stress the memory sub-system to make it more expensive to allocate memory.
The tests are repeated 4 times and averaged. The test are built using Visual Studio 2010 and 2013 and
run on Windows 7/x64.
The graph shows relative performance of each STL container by compiler.
All builds are targeted for x64. VS2010 and VS2013 have similar results with 2013 slightly flaster execution.
HasMpAlloc is HashMap and MapAlloc is Map, bound with my custom pool allocator.
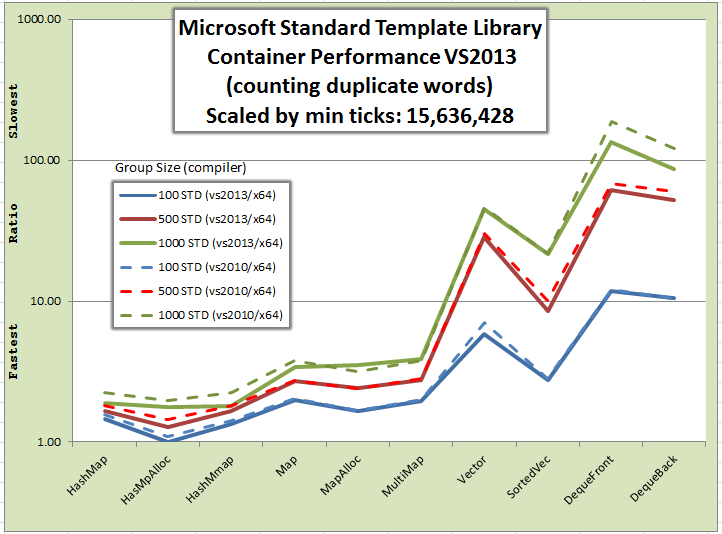
Boost has simmilar performance to Microsoft's std containers.
Boost flat_map is slower then map.
MapAlloc is std::map with my custom pool allocator and flat_map is Boost's flat memory map container.
Tabular Test Results
Each compiler configuration produces an executable which generates scaled results.
The results are scaled against the fastest results in the suite revealing how the containers perform
relative to each other independent of the cpu speed.
Jan 2015
Container Performance to count unique words.
x64 application, dual quad core Intel Xeon E5440 2.83Ghz
 Visual Studio 2013 target x64
Visual Studio 2013 target x64
 Microsoft Standard Template Library
Microsoft Standard Template Library
Performance (1.00=fastest) - Ratio of elapsedTicks/fastestTicks(15,634,428):
| Group Size | HashMap | HasMpAlloc | HashMmap | Map | MapAlloc | MultiMap | Vector | SortedVec | DequeFront | DequeBack
|
| 100 | 1.45 | 1.00 | 1.35 | 1.98 | 1.66 | 1.94 | 5.85 | 2.74 | 11.87 | 10.55
|
| 500 | 1.65 | 1.28 | 1.66 | 2.71 | 2.43 | 2.74 | 28.41 | 8.51 | 61.06 | 52.31
|
| 1000 | 1.90 | 1.78 | 1.81 | 3.41 | 3.50 | 3.87 | 45.22 | 21.39 | 134.60 | 86.83
|
Memory - Number of Memory Allocations called
HasMpAlloc and MapAlloc use custom allocator which reduces memory allocations.
| Group Size | HashMap | HasMpAlloc | HashMmap | Map | MapAlloc | MultiMap | Vector | SortedVec | DequeFront | DequeBack
|
| 100 | 7204 | 8 | 7204 | 7201 | 6 | 7201 | 1 | 1 | 7561 | 7561
|
| 500 | 6504 | 8 | 6504 | 6501 | 6 | 6501 | 1 | 1 | 6592 | 6592
|
| 1000 | 6005 | 9 | 6005 | 6001 | 6 | 6001 | 1 | 1 | 6049 | 6049
|
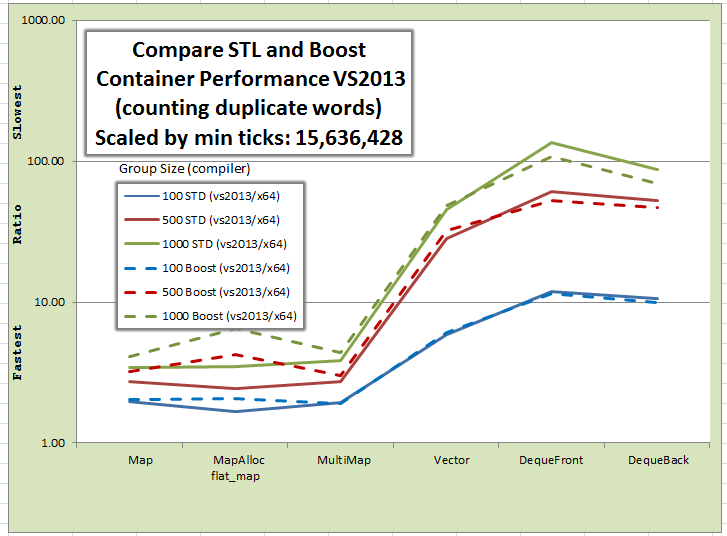
 Boost 1.57 Container Performance
Boost 1.57 Container Performance
Performance (1.00=fastest) - Ratio of elapsedTicks/fastestTicks(29,787,329):
| Group Size | map | flat_map | MuliMap | Vector | DequeFront | DequeBack
|
| 100 | 1.06 | 1.09 | 1.00 | 3.20 | 6.08 | 5.22
|
| 500 | 1.69 | 2.22 | 1.58 | 16.97 | 27.36 | 24.43
|
| 1000 | 2.14 | 3.38 | 2.30 | 25.57 | 56.92 | 36.63
|
Memory - Number of Memory Allocations called
| Group Size | map | flat_map | MuliMap | Vector | DequeFront | DequeBack
|
| 100 | 7200 | 8 | 7200 | 1 | 601 | 577
|
| 500 | 6500 | 10 | 6500 | 1 | 543 | 534
|
| 1000 | 6000 | 11 | 6000 | 1 | 501 | 499
|
Notes:
- Smaller Group Size refill more often, benefiting from custom allocator (HashAlloc and MapAlloc).
- Default Hash containers are slightly faster then non-hash equivalents (HashMap vs Map and HashMultiMap vs MultiMap)
- Deque has worse performance, both speed and allocations.
Conclusion
- The custom allocator reduces memory allocation calls a lot but only slightly reduces execution time.
Meaning more time is spent in searching the contaners than calling malloc so the custom allocate adds little benefit.
- VS2010 hash versions are significantly faster than their non-hash equivalents.
- Vector is the slow because it does a linear lookup. The Sorted Vector test uses a binary search is faster but still slow.
- No surprise Deque and Vector are not well suited to this test scenario since they are not an ordered container.
[ Top ]
Summary of compiled execution speed
The Compiler comparison table shows the fastest tick count when running the Container test suite.
Good news, each released compiler generates more efficient code then its predecessor.
Jan-2015
Compiler STL comparison
Dual quad core Intel Xeon E5440 2.83Ghz
| Compiler | Fastest
Tick Count
|
| vs2013/x64 | 15,634,428
|
vs2010/x64  | 17,069,494
|
vs2008/x64  | 58,195,100
|
Blog about C++ STL Performance


