Thread Local Memory Access Penalty

Dennis Lang
landenlabs.com
Updated: 31-Aug-2009
In our quest to maximize performance, we often turn to threads. Per Herb Sutter's article, we need to watch out for hidden performance penalties caused by cpu cache collisions. If two or more threads try to access memory which is currently in another cpu's cache there may be an added delay.
Please read the following articles for the full briefing on this topic.
To help illustrate this phenomenon I created a small threaded test application to measure the penalty. Each thread gets a 4byte counter. The counter's position in memory is decided based on the distance requested at run time. Each thread runs as fast as possible, incrementing and touching the memory location. Each thread exits after completing a requested number of iterations. The elapsed time for all threads to exit is recorded.
Thread_return_t WINAPI run_test(void* threadData)
{
// Get thread number
int threadNum = (int)threadData;
// Calculate pointer to our counter.
volatile Counter_t& counter = g_pCounter[threadNum * g_distance];
for (unsigned long i = 0; i < g_iteration_count; i++)
{
// Increment counter which is a specific distance apart.
counter++;
// Exercise counter to slow down the loop some.
if ((counter & 0x5555) == counter << 2)
{
counter++;
}
}
}
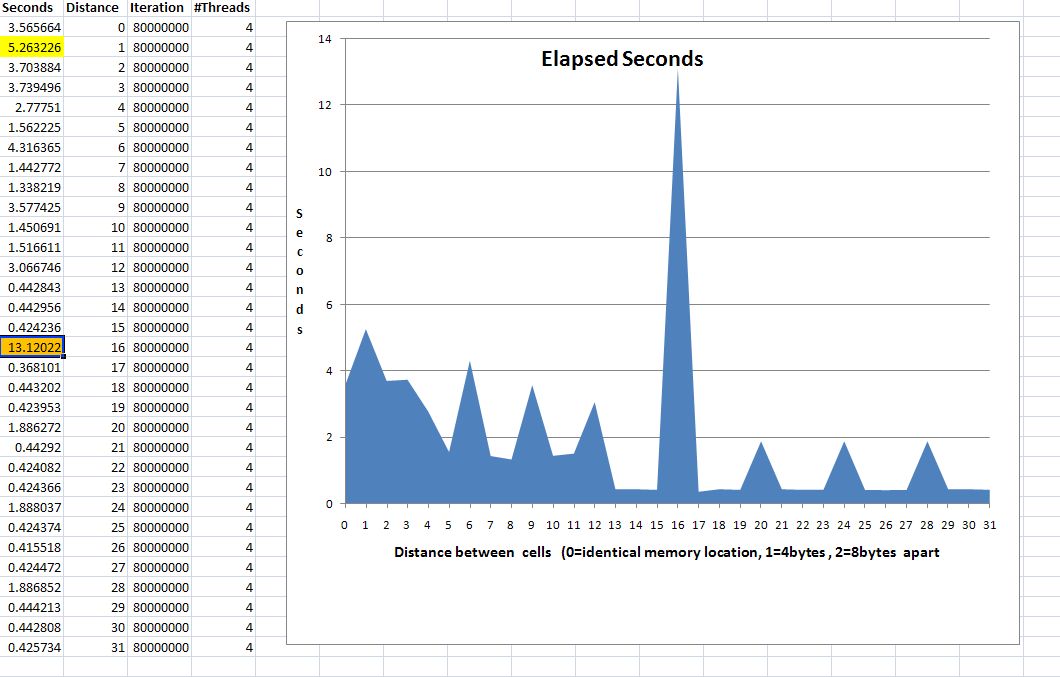
The resulting graph shows that accessing memory close to another threads is slow and has a 'thread locality' penalty. The further apart the thread addresses, the lower the penalty. All of my testing, on various chip configurations, produce an unusually large spike at 12 to 18 units apart. The L1 cache line size is 64 bytes on my HP8600, which matches the spike at 16 units (4bytes per unit). I don't know why it spikes as it hits the edge of the cache line size.
The test was run on a HP8600 2 quad core Xeon 2.86 Ghz chips. The processor affinity mask was left at its default setting. The program was run on XP/32, but I got similar results running on Linux RedHat and on both Intel and AMD chips. The results were similar when I set the thread affinity to run one thread per cpu (as one would expect).